

How we might be squandering generative AI's potential
What I learned from a start-up exploration

The first startup idea I explored after leaving Google was concerned with automating aspects of grocery and retail operations. Estimating exactly how many items are on shelves affects a variety of business metrics from shrink (discrepancies between the physical amounts and recorded amounts due to damaged goods, shoplifting, data entry errors, etc.) to stockouts (loss of revenue due to items not being on shelves while still being in the store). The business potential wasn’t lost on other entrepreneurs, with a lot of companies working towards solutions (robots, more robots, cameras, more cameras).
As I built models, I sought to create a fair comparison with their state-of-the-art generative AI counterparts, only to find myself dissatisfied by the options that generative AI was offering me. As I dug deeper, it became clearer that getting to a fair comparison meant rethinking how to use generative AI itself.
Flavors of Generative AI
Most people experience generative AI in a chat window. They type something in, maybe drag in an image or a document for context, hit enter, and then wait for the model to provide an output.
Technically, the output originates from a model that acts as a conditional probability distribution over the next token in a sequence for a given input. There are various ways to generate an output given this model, but two flavors predominate: sampling approaches and the most probable sequence (or tractable approximations).
Sampling approaches are analogous to the information theoretic concept of drawing from a typical set, which turn out asymptotically to be where all the probability is concentrated. In the generative AI world, it allows for “diversity [in outputs] while effectively truncating the less reliable tail of the distribution.”
Likewise, forcing a model to output the most probable sequence has its place in tasks where there is only one objective right answer (e.g. “In base 10, 1 + 1 = ”).
However, there are broad applications of interest in which neither of these approaches is the correct one, and can be shown to be suboptimal.
We Ignore the Model’s Ability to Hedge
Any approach that uses sampling effectively generates an output that is itself random, but essentially commits to one possible answer within the space of all possible outputs. This breaks down when committing to a specific sample is worse than hedging across the distribution, which is a common occurrence in decision problems.
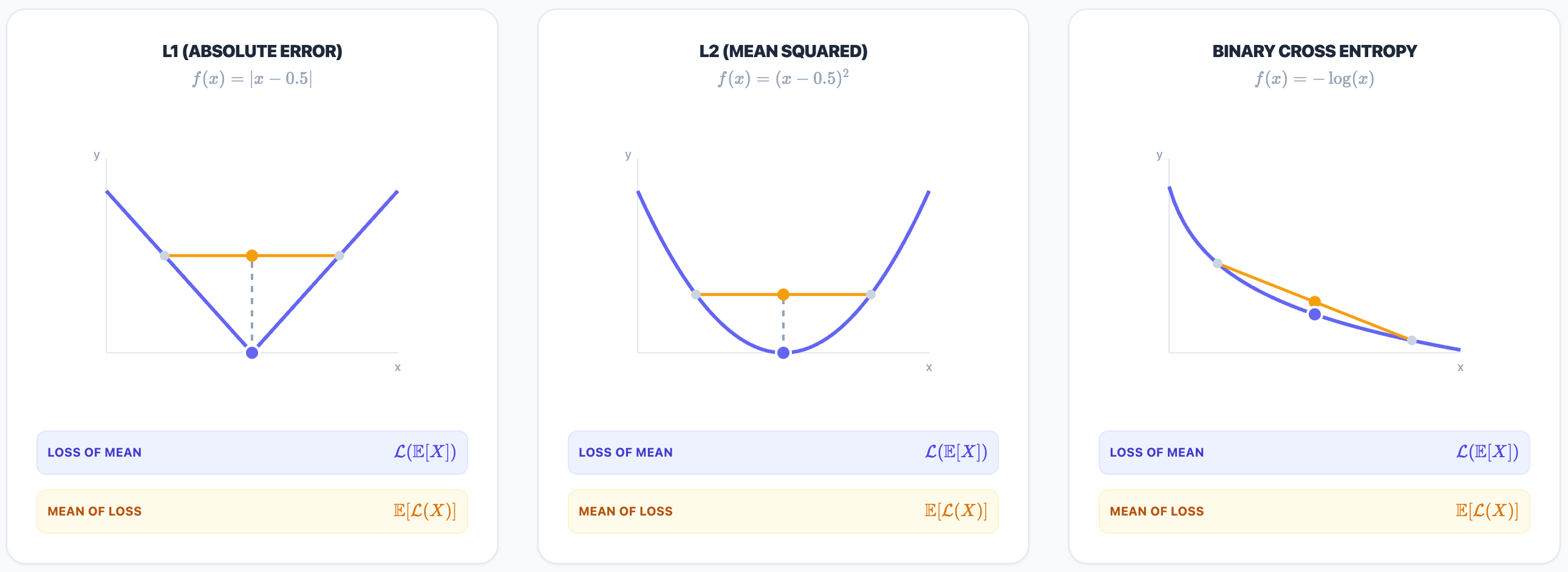
For instance, suppose someone is trying to estimate a numerical quantity in which the correct answer is 0.5, and they have a particular notion of error with which they want to measure the output against (e.g. absolute error, squared error, or if it’s a probability, binary cross entropy). It turns out that by committing to an answer, we end up doing worse on average than if our answer were simply an average over the possible sample outputs. This can be seen visually in the above figure across absolute error, squared error, and binary cross entropy, in which the orange dot represents an average error over individual samples, and the blue dots represent the error evaluated on the average across the samples.
A student of probability theory knows that this is simply a consequence of Jensen’s inequality for a convex loss, which is true for all the error functions considered above:
I decided to test this idea out over parts of the inventory eval set for grocery retail, which has some tricky cases involving partial or full occlusion of items. It turns out that by taking advantage of this idea, I can get Google’s open weight Gemma 4 to generate custom point estimates that not only beat Gemma 4 with a more standard sampled decoding approach,1 but also proprietary models in OpenAI’s GPT 5 family. As an exercise for the interested reader who may want to try out a similar experiment, the SentencePiece tokenizer used by Gemma 4 has individual tokens for the digits 0 through 9.
The Answer is in the Eyes of the Beholder
One objection to the above is that it assumes the decoding method of the model is sampling, but we had also discussed choosing the most probable sequence or an approximation to it. However, we run into a separate issue here, because the most probable sequence is making an implicit assumption about the error of interest, which might not match our actual error of interest.
Consider the motivating problem from retail, in which one department may be interested in estimating shrink while another is interested in estimating stockouts. While estimating shrink might require an unbiased estimate of the physical inventory count, stockout estimation might favor an underestimate to an overestimate as it is often better to have surplus inventory to avoid lost sales than to run out.
The problem is that an API that outputs the most probable sequence doesn’t let the end user make that choice based on the underlying probabilities within the model, and similarly to the eval experiment in the previous section, it’s straightforward to generate point estimates that are on the Pareto frontier when you have access to the lower level information about the underlying probabilities. It’s worth noting that OpenAI, Anthropic, and Google have moved in a direction with their APIs in which these kinds of methods are harder to explore.
One might counter that the burden is then on the user to provide all the tradeoffs that are important to them up front, but if the retort is, “Ask the question better,” it basically negates the idea that these models are in fact supposed to be easy to use and can solve all our problems, revealing a gap between the powerful AI coding agents and conversationalist chatbots that exist today and those aspirational systems that can help us make more informed decisions in the face of uncertainty.
Strictly speaking, in addition to Jensen’s inequality, the experiment also relies on Hoeffding’s inequality with the assumption that this is happening over a large enough eval set.